面试问题(一)Java集合
准备了半个多月实习,虽然没有收到一个好结果,但在这个过程中不断总结,觉得还是学会了很多东西,分享一下已经总结过的面试知识点,以后一定还会持续更新!
Java集合
Java集合主要包括两种容器:Collection和Map。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
1. List、set、map三者的区别
List有序可重复,Set无序不可重复。Map存储键值对,key无序不可重复,value无序可重复。 #### 2. ArrayList和LinkedList的区别 • 从底层结构:ArrayList底层是Object[]数组,LinkedList底层是双向链表。对ArrayList来说,访问元素复杂度为O(1),插入删除元素复杂度O(n);对LinkedList,插入删除元素复杂度为O(n),获取头尾元素复杂度为O(1)。 • 从线程安全:都是不安全的。(Vector线程安全) #### 3. HashMap源码说一下(细说,从初始化到put、get、扩容、红黑树、1.8做了哪些优化) 一、初始化 1.7时,HashMap底层结构为数组+链表,形成链表散列。提供了四个重载的构造方法,初始化参数,主要是initialCapacity 初始容量,默认为16,和load factor负载因子默认为0.75。
二、put,get操作 table数组,存放Entry对,每个存放元素的位置称为桶。 当put(key,value)时,计算key的hashcode,再通过扰动函数得到hash值,hash & (n - 1)即为桶的索引,也就是存放位置。当此位置没有元素,直接加入;若已有一个或多个元素(链表形式),调用equals()方法,若返回false,直接加入;若返回true,无法加入。 当get(key)时,根据key值计算hash,得到存放的数组索引,遍历对应的Entry对象链表,若有equals()返回true的entry返回value的值;否则,返回空。
三、扩容 首先什么时候要扩容呢? 当超过(load factor * current capacity),就要进行扩容。比如初始值为16和0.75,意味着最多放12个元素,一旦超过12个,就需要扩容。
为什么扩容是2的n次幂? 为了存取高效,减少碰撞,应使每条链表的长度大致相同,采用取模运算,即 hash % length。但取模没有位运算高效,源码中通过 hash & (length-1)来实现。那么length为2的n次幂时,相当于与n个1进行与运算,更加减少碰撞。比如 len=8,2&(len-1)=2,3&(len-1)=3;len=5,2&(len-1)=0,3&(len-1)=0。
四、红黑树 jdk1.8 底层数据结构为数组+链表/红黑树,当链表长度大于阈值(默认8),且数组长度大于等于64时,会转化成红黑树,否则对数组进行扩容。
五、1.8优化 • 由数组+链表的结构改为数组+链表+红黑树。 • 简化了hash方法:h^(h>>>16),原理不变,1.7需要扰动4次。 • 扩容后,元素要么是在原位置,要么是在原位置再移动2次幂的位置,且链表顺序不变。
4. Hashmap链表要转红黑树,为什么阈值为8?
当链表长度大于8且数组长度大于等于64时,要转成红黑树;当红黑树大小为6时又退化成链表。和hashcode碰撞次数的泊松分布有关,主要为了寻找一种时间和空间的平衡。负载因子为0.75时,单个hash桶内元素个数为8的概率已经很小了。将7作为缓冲,等于7时不作转换,大于8时转为红黑树,小于等于6时转为链表。选择8是从概率统计角度选择的。 #### 5. 多线程Put可能发生的问题 当多线程执行put操作,会造成死循环。HashMap不是线程安全的,在并发执行put()时会发生扩容,可能会导致节点丢失,产生环形链表等情况,会导致get()方法出现死循环。 并发时推荐使用ConcurrentHashMap。 #### 6. ConcurrentHashMap的实现 jdk1.7 采用分段锁的思想,将HashMap的数组分割成小数组(Segment),Segment类继承了ReentrantLock(可重入锁)。每个Segment由HashEntry组成,HashEntry用于存储键值对数据。每把锁只锁容器的一部分数据,多线程访问容器里不同数据段的数据,不会存在锁竞争,提高并发访问率。 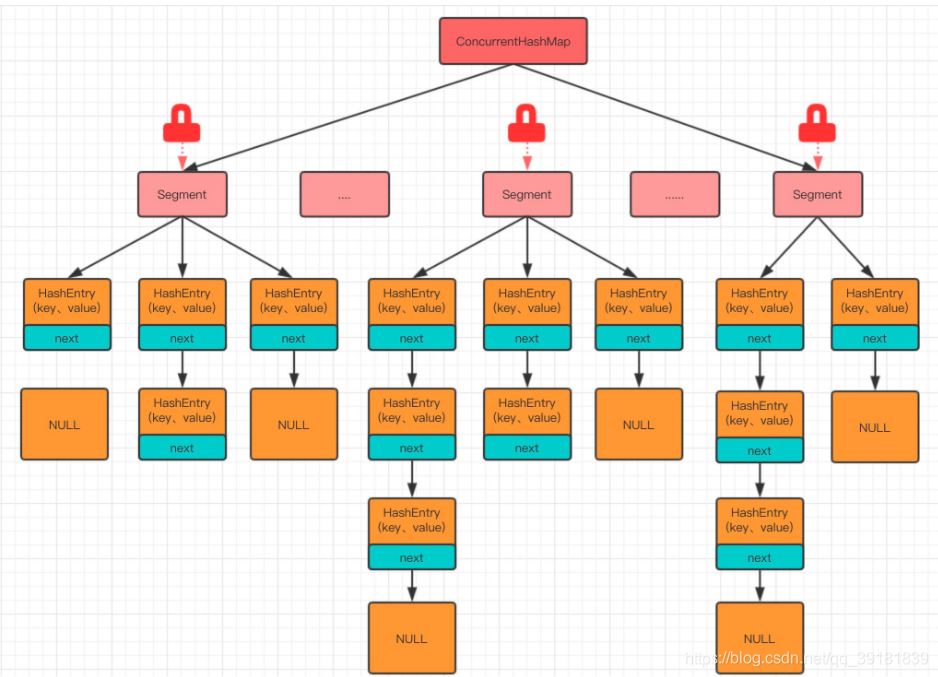
jdk1.8 摒弃了Segment分段锁,采用CAS+Sychronized保证并发安全。底层结构与HashMap相同,都是数组+链表/红黑树。Sychronized只锁当前链表或红黑树的首节点,这样只要hash不冲突,就不会产生并发,提高了效率。 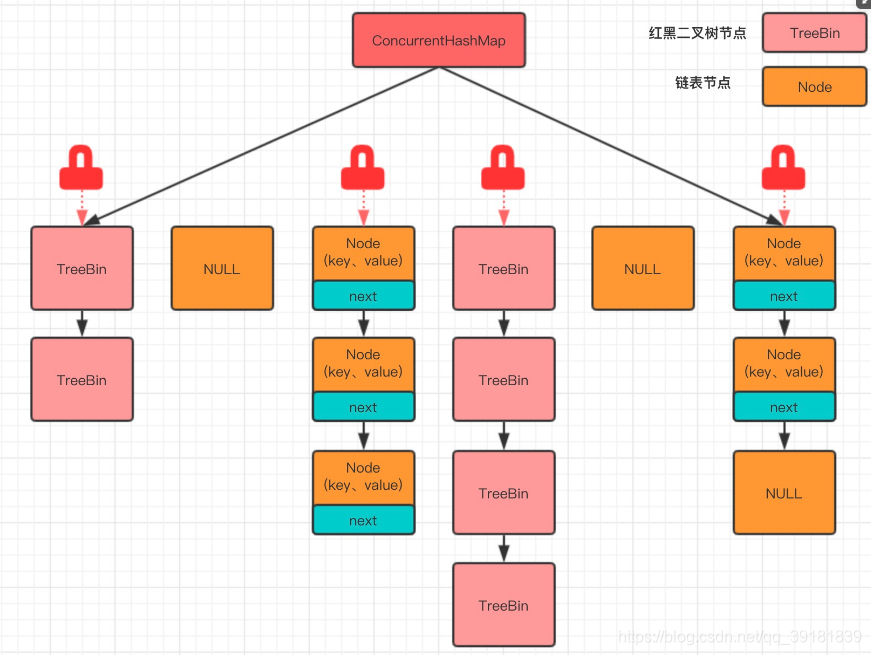
7. ConcurrantHashMap和HashTable的区别
• 从底层数据结构:HashTable和1.8之前的HashMap类似,采用数组+链表的结构。ConcurrentHashMap在1.7使用Segment数组(包含HashEntry数组)+链表,在1.8与HashMap1.8一样,使用分段数组+链表/红黑树。 • 从线程安全:HashTable使用全表锁,线程安全。ConcurrentHashMap在1.7采用分段锁,每把锁只锁容器的一部分数据,多个线程同时访问不同数据段的数据,提高了并发效率;在1.8使用CAS+Synchronized,Synchronized只锁链表或红黑树的首节点,只要hash不冲突,就不会产生并发安全问题。 #### 8. ConcurrantHashMap的 size如何计算 无论是JDK1.7还是JDK1.8中,ConcurrentHashMap的size()方法都是线程安全的,都是准确的计算出实际的数量,但是这个数据在并发场景下是随时都在变的。 调用size()方法会调用sumCount()方法,map 中键值对的个数通过求 baseCount 与 counterCells 非空元素的和得到。如果没有冲突,只将size的变化写入baseCount。发生冲突就用数组(counterCells)来存储后续size的变化。 #### 9. LinkedHashMap,如何在O(1)的时间里面删除一个元素 LinkedHashMap底层使用双向链表,每个节点包含两个指针:前驱节点和后继节点。删除节点时将前继节点的后继指针指向删除节点的后继节点,将后继节点的前驱指针执行删除节点的前继节点。即实现删除此元素。 HashMap存储的key无序,如果要求key有序,需要使用TreeMap,但选择TreeMap会有性能问题,时间复杂度为O(logn)。而LinkedHashMap可以平衡这些因素,能以O(1)时间复杂度查找元素,又保证key的有序性。 LinkedHashMap提供了两种key的顺序: • 访问顺序,可以实现LRU缓存 • 插入顺序,同一个key多次插入,不影响其顺序 #### 10. HashSet和HashMap的区别 首先HashSet实现了Set接口,HashMap实现了Map接口。 • 从底层数据结构:HashSet底层基于HashMap实现。 • 从线程安全:都不安全 • 从存储对象:HashSet存储无序,不可重复的元素,HashMap存储键值对,key和value都可以为null。 • 从添加元素:HashSet使用add()添加元素,HashMap使用push()方法添加元素。 #### 11. HashTable与hashMap的不同 • 从底层数据结构:HashTable底层为数组+链表,jdk8之后的HashMap在解决哈希冲突时有了较大变化,当链表长度大于8且数组长度大于64时转化为红黑树。HashTable没有这样的机制。 • 从线程安全:HashMap线程不安全,HashTable的实现方法都添加了Synchronized关键字来保证线程安全。 • 对 null key 和 null value的支持:HashMap可以存储null key和null value,但null key只有一个,null作为值可以有多个。HashTable不支持 null key 和 null value。 • 初始容量和扩容机制的不同:HashMap初始容量为16,每次扩为2倍(2次幂是为了减少碰撞);HashTable初始容量为11,每次扩容为2n + 1。 #### 12. 自定义的类作为HashMap的key需要注意什么? 需要重写equals()方法和hashcode()方法。 举个例子: public class Main {
public static void main(String[] args) {
HashMap<Person, String> map = new HashMap<Person, String>();
map.put(new Person("001"), "findingsea");
map.put(new Person("002"), "linyin");
map.put(new Person("003"), "henrylin");
map.put(new Person("003"), "findingsealy");
System.out.println(map.toString());
System.out.println(map.get(new Person("001")));
System.out.println(map.get(new Person("002")));
System.out.println(map.get(new Person("003")));
}
}public class Person {
private String id;
public Person(String id) {
this.id = id;
}
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
if (id != null ? !id.equals(person.id) : person.id != null) return false;
return true;
}
public int hashCode() {
return id != null ? id.hashCode() : 0;
}1. {Person@ba31=findingsea, Person@ba32=linyin, Person@ba33=findingsealy}
2. findingsea
3. linyin
4. findingsealypublic static void main(String[] args) {
List<String> platformList = new ArrayList<>();
platformList.add("博客园");
platformList.add("CSDN");
platformList.add("掘金");
Iterator<String> iterator = platformList.iterator();
while (iterator.hasNext()) {
String platform = iterator.next();
if (platform.equals("博客园")) {
iterator.remove();
}
}
System.out.println(platformList);
}public static void main(String[] args) {
List<String> platformList = new ArrayList<>();
platformList.add("博客园");
platformList.add("CSDN");
platformList.add("掘金");
for (int i = 0; i < platformList.size(); i++) {
String item = platformList.get(i);
if (item.equals("博客园")) {
platformList.remove(i);
i = i - 1;
}
}
System.out.println(platformList);
}public static void main(String[] args) {
List<String> platformList = new ArrayList<>();
platformList.add("博客园");
platformList.add("CSDN");
platformList.add("掘金");
for (int i = platformList.size() - 1; i >= 0; i--) {
String item = platformList.get(i);
if (item.equals("掘金")) {
platformList.remove(i);
}
}
System.out.println(platformList);
}